
ผลิตภัณฑ์
19
Jan
การวินิจฉัยและการพยากรณ์ความผิดพลาดของหม้อแปลงไฟฟ้าขนาดใหญ่โดยอาศัยทฤษฎีหลักฐาน DBNC และ D-S
บทความนี้จะอธิบายวิธีการวินิจฉัยและคาดการณ์ความผิดพลาดในหม้อแปลงไฟฟ้าขนาดใหญ่

เชิงนามธรรม
หม้อแปลงไฟฟ้าเป็นอุปกรณ์หลักของระบบไฟฟ้า ซึ่งทำหน้าที่สำคัญในการส่งและแปลงกระแสไฟฟ้า และการทำงานที่ปลอดภัยและเสถียรมีความสำคัญอย่างยิ่งต่อการทำงานปกติของระบบไฟฟ้าทั้งหมด เนื่องจากโครงสร้างที่ซับซ้อนของหม้อแปลงไฟฟ้า การใช้ข้อมูลเดี่ยวสำหรับการบำรุงรักษาตามสภาพ (CBM) จึงมีข้อจำกัดบางประการ ด้วยความช่วยเหลือของเทคโนโลยีการตรวจสอบเซ็นเซอร์ขั้นสูงและการรวมข้อมูล ข้อมูลจากหลายแหล่งจึงถูกนำมาใช้ในการพยากรณ์และการจัดการสุขภาพ (PHM) ของหม้อแปลงไฟฟ้า ซึ่งเป็นวิธีสำคัญในการบรรลุ CBM ของหม้อแปลงไฟฟ้า บทความนี้นำเสนอวิธีการที่ผสมผสานทฤษฎีเครือข่ายความเชื่อเชิงลึก (DBNC) และทฤษฎีหลักฐาน DS และนำมาประยุกต์ใช้กับ PHM ของหม้อแปลงไฟฟ้าขนาดใหญ่ ผลการทดลองแสดงให้เห็นว่าวิธีการที่เสนอมีอัตราการวินิจฉัยข้อบกพร่องที่ถูกต้องสูงสำหรับหม้อแปลงไฟฟ้าด้วยข้อมูลหลายแหล่งจำนวนมาก
1. บทนำ
หม้อแปลงไฟฟ้าเป็นอุปกรณ์สำคัญในระบบไฟฟ้าที่มีโครงสร้างภายในที่ซับซ้อนและความผิดพลาดหลายประเภท ปัจจุบัน วิธี PHM ของหม้อแปลงไฟฟ้าส่วนใหญ่ใช้ปัจจัยบางอย่างหรือปัจจัยหลายประการในการตัดสินใจ โดยไม่ได้คำนึงถึงสภาพการทำงานโดยรวมของหม้อแปลง ข้อมูลข้อบกพร่อง ประวัติการบำรุงรักษา ประวัติครอบครัว และข้อมูลสถานะอื่นๆ ที่ครอบคลุม เนื่องจากข้อจำกัดของวิธีการทดสอบ ความไม่แม่นยำของความรู้ และเหตุผลอื่นๆ ดังนั้น ข้อมูลจึงมีลักษณะคลุมเครือและสุ่ม และคำอธิบายที่ชัดเจนของฝ่ายปฏิบัติการและบำรุงรักษาเกี่ยวกับปฏิสัมพันธ์ของคัปปลิ้งภายในและวิวัฒนาการของความผิดพลาดของหม้อแปลงจึงไม่เพียงพอ สำหรับความไม่แน่นอนของ PHM ของหม้อแปลงไฟฟ้า ความแม่นยำและความทันท่วงทีของผลการวินิจฉัย การพยากรณ์ และการจัดการข้อบกพร่องยังห่างไกลจากข้อกำหนดในทางปฏิบัติ
เทคโนโลยีฟิวชั่นข้อมูลหลายแหล่งเป็นเทคโนโลยีการประมวลผลข้อมูลใหม่ที่พัฒนาขึ้นในช่วงไม่กี่ปีที่ผ่านมา เทคโนโลยีนี้ใช้ประโยชน์จากทรัพยากรเซ็นเซอร์หลายตัวได้อย่างเต็มที่ และผสานรวมข้อมูลเสริมและข้อมูลซ้ำซ้อนของเซ็นเซอร์ต่างๆ ทั้งในเชิงพื้นที่และเวลาตามเกณฑ์การปรับให้เหมาะสมที่สุด เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด เพิ่มความอยู่รอดของระบบ ขยายขอบเขตเชิงพื้นที่และเวลา เพิ่มความน่าเชื่อถือของผลลัพธ์ และลดความคลุมเครือของข้อมูล เทคโนโลยีฟิวชั่นข้อมูลหลายแหล่งที่ใช้ใน PHM ของหม้อแปลงไฟฟ้าสามารถชดเชยข้อเสียของแหล่งข้อมูลเดียวในวิธี PHM แบบดั้งเดิมได้ เทคโนโลยีนี้สามารถวิเคราะห์ข้อมูลที่มีศักยภาพจากข้อมูลลักษณะเฉพาะของหม้อแปลงไฟฟ้าที่ซับซ้อนจำนวนมากได้อย่างแม่นยำและมีประสิทธิภาพ เพื่อตรวจสอบสภาพของหม้อแปลงและคาดการณ์ความผิดพลาดของหม้อแปลงไฟฟ้า ลดความเสียหายที่เกิดจากความผิดพลาดของหม้อแปลงไฟฟ้า และรับรองการทำงานที่ปลอดภัยและเสถียรของระบบไฟฟ้า
2. ทฤษฎี PHM และ DBN
2.1. ภารกิจหลักของ PHM
PHM มีเป้าหมายเพื่อยืดอายุการใช้งานของอุปกรณ์วิศวกรรม พร้อมกับลดต้นทุนการพัฒนาและการบำรุงรักษา วงจร PHM ของหม้อแปลงไฟฟ้าประกอบด้วยสามส่วนหลัก ได้แก่ การวินิจฉัยข้อบกพร่อง การพยากรณ์ข้อบกพร่อง และการบำรุงรักษาตามสภาพ วัตถุประสงค์ของการวินิจฉัยข้อบกพร่องคือการวินิจฉัยและระบุสาเหตุหลักของความล้มเหลวของหม้อแปลง สาเหตุหลักสามารถให้ข้อมูลที่เป็นประโยชน์สำหรับแบบจำลองการพยากรณ์ รวมถึงข้อมูลป้อนกลับสำหรับการปรับปรุงการออกแบบหม้อแปลง Prognostic จะนำข้อมูลที่ประมวลผลแล้ว รวมถึงแบบจำลองระบบที่มีอยู่หรือการวิเคราะห์โหมดความล้มเหลวเป็นอินพุต จากนั้นใช้อัลกอริทึมการพยากรณ์เพื่ออัปเดตแบบจำลองการเสื่อมสภาพแบบออนไลน์ และคาดการณ์ระยะเวลาความล้มเหลวของหม้อแปลงไฟฟ้า CBM คือการใช้ผลลัพธ์จากการพยากรณ์ โดยพิจารณาต้นทุนและประโยชน์ของการบำรุงรักษาที่แตกต่างกัน เพื่อกำหนดเวลาและวิธีการบำรุงรักษาเชิงป้องกันเพื่อลดต้นทุนการดำเนินงานและความเสี่ยง
เหนือสิ่งอื่นใด งานทั้งสามนี้จำเป็นต้องดำเนินการแบบไดนามิกและแบบเรียลไทม์ บทความนี้นำเสนอวิธีการใหม่สำหรับการวินิจฉัยข้อบกพร่องของหม้อแปลงไฟฟ้า แผนการวิจัย PHM ของหม้อแปลงไฟฟ้ากำลังขนาดใหญ่ ดังแสดงใน รูปที่ 1
2.2. เครือข่ายความเชื่อเชิงลึก
Deep Belief Network (DBN) เป็นวิธีการเรียนรู้เชิงลึกชนิดหนึ่ง ที่มีความสามารถในการดึงคุณลักษณะจากตัวอย่างจำนวนมาก เพื่อจำแนกประเภทและปรับปรุงความแม่นยำในการจำแนกประเภท วิธีนี้ประสบความสำเร็จ

เมื่อนำไปใช้กับปัญหาการจำแนกประเภท และแสดงข้อดีบางประการ ถือเป็นจุดสำคัญของการวิจัยระดับนานาชาติในปัจจุบันเกี่ยวกับการเรียนรู้ของเครื่องจักร
DBN ถูกเสนอโดยศาสตราจารย์เจฟฟรีย์ ฮินตัน ในปี พ.ศ. 2549 ซึ่งเป็นแบบจำลองเชิงสร้างความน่าจะเป็นเพื่อสร้างการแจกแจงความน่าจะเป็นร่วมระหว่างข้อมูลที่สังเกตได้และป้ายกำกับ โดยประเมินทั้ง P (การสังเกต|ป้ายกำกับ) และ P (การสังเกต|ป้ายกำกับ) โครงสร้างนี้ประกอบด้วยเครื่อง Restricted Boltzmann Machines (RBM) หลายเครื่องซ้อนกัน โดยใช้วิธีการฝึกแบบเลเยอร์ต่อเลเยอร์ วิธีนี้ช่วยแก้ปัญหาการฝึกที่วิธีการฝึกแบบโครงข่ายประสาทเทียม (NN) แบบดั้งเดิมไม่เหมาะสำหรับเครือข่ายหลายชั้น โดยการฝึก DBN แบ่งออกเป็นสองขั้นตอน ได้แก่ ขั้นตอนก่อนการฝึกและขั้นตอนการปรับแต่ง
2.2.1. การฝึกอบรมเบื้องต้น
การเตรียมการล่วงหน้าเป็นกระบวนการพื้นฐานที่เริ่มต้นพารามิเตอร์เครือข่าย โดยใช้อัลกอริทึมการเพิ่มประสิทธิภาพคุณลักษณะแบบไม่มีผู้ดูแลแบบเลเยอร์ต่อเลเยอร์ พารามิเตอร์เครือข่ายที่เริ่มต้นคือน้ำหนักการเชื่อมต่อระหว่างเลเยอร์และค่าออฟเซ็ตของนิวรอนแต่ละเลเยอร์ เป็นตัวอย่างเพื่อแนะนำโครงสร้างแบบลำดับชั้นของ RBM ดังแสดงใน รูปที่ 2
RBM ประกอบด้วยเลเยอร์ที่มองเห็นได้ และเลเยอร์ที่ซ่อนอยู่ไม่มีการเชื่อมต่อระหว่างหน่วยของเลเยอร์แต่ละชั้น แต่เชื่อมต่อกันอย่างสมบูรณ์ระหว่างเลเยอร์ สมมติว่า เลเยอร์มี หน่วยที่มองเห็นได้ เลเยอร์มี หน่วยที่ซ่อนอยู่ ดังนั้น RBM ในฐานะพลังงานของระบบจึงนิยามได้ตามสมการ (1):
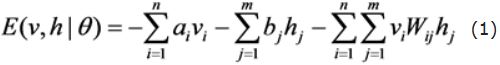
โดยที่ Vi คือ เงื่อนไขของ i หน่วยที่มองเห็นได้หน่วยแรก, hj คือ เงื่อนไขของ j หน่วยที่ซ่อนอยู่หน่วยแรก, 0={Wij,ai,bj} คือ พารามิเตอร์ RBM, Wij คือ น้ำหนักการเชื่อมต่อระหว่างหน่วยที่มองเห็นได้ I และหน่วยที่ซ่อนอยู่, j คือ ค่าออฟเซ็ตของหน่วยที่มองเห็นได้, คือ ค่าออฟเซ็ตของหน่วยที่ซ่อนอยู่ จากฟังก์ชันพลังงาน สามารถหาการแจกแจงความน่าจะเป็นร่วม (v,h) ของสมการ (2):

โดยที่

คือปัจจัยการทำให้เป็นมาตรฐาน กล่าวคือ ฟังก์ชันการแบ่งส่วน การกระจายตัวส่วนเพิ่ม (หรือที่เรียกว่าฟังก์ชันความน่าจะเป็น) ของการแจกแจงความน่าจะเป็นร่วม
สามารถแสดงเป็นสมการ (3):
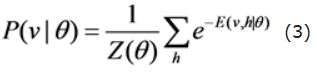
2.2.2. การปรับแต่ง
หลังจากการฝึกอบรมเบื้องต้นเสร็จสิ้น แต่ละชั้นของ RBM จะสามารถรับพารามิเตอร์การเริ่มต้นระบบ สร้างกรอบการทำงานเบื้องต้นของ DBN จากนั้นจึงจำเป็นต้องปรับแต่งการฝึกอบรมสำหรับ DBN และปรับแต่งพารามิเตอร์ของแต่ละชั้นเครือข่ายเพิ่มเติม เพื่อเพิ่มประสิทธิภาพการแยกแยะเครือข่าย กระบวนการปรับแต่งเป็นกระบวนการเรียนรู้แบบมีผู้สอน คือการใช้ข้อมูลที่ไม่มีป้ายกำกับในการฝึกอบรม จากนั้นจึงใช้อัลกอริทึม BP ในการปรับแต่งพารามิเตอร์เครือข่ายอย่างละเอียด เพื่อให้ได้เครือข่ายที่ดีที่สุดทั่วโลก ประสิทธิภาพจะเหนือกว่าผลของการฝึกอบรมอัลกอริทึม BP เนื่องจากต้องการเพียงการค้นหาพื้นที่พารามิเตอร์เครือข่ายในพื้นที่ เมื่อเทียบกับเครือข่ายประสาทเทียม BP ความเร็วในการฝึกอบรมจะรวดเร็วและเวลาในการบรรจบกันสั้น
3. แบบจำลองการรวมข้อมูลหลายแหล่งของ PHM ของหม้อแปลงไฟฟ้า
การรวมข้อมูลหลายแหล่งเกี่ยวข้องกับหลายแง่มุมของทฤษฎีและเทคโนโลยี ได้แก่ การประมวลผลสัญญาณ ทฤษฎีการประมาณค่า ทฤษฎีฟัซซี การวิเคราะห์คลัสเตอร์ เครือข่ายประสาทเทียม และปัญญาประดิษฐ์ เป็นต้น การรวมข้อมูลสามารถแบ่งได้เป็น 3 ระดับ ได้แก่ การรวมข้อมูล การรวมคุณลักษณะ และการรวมการตัดสินใจ วิธีการหลักที่ใช้ ได้แก่ การอนุมานแบบเบย์เซียน ทฤษฎีหลักฐาน DS ทฤษฎีฟัซซี ระบบผู้เชี่ยวชาญ และอื่นๆ
ทฤษฎีหลักฐาน DS ถูกเสนอโดย Dempster ในปี 1967 จากนั้น Shafer ได้ขยายและพัฒนาทฤษฎีหลักฐานนี้ ดังนั้นทฤษฎีหลักฐานจึงถูกเรียกว่าทฤษฎีหลักฐาน DS ทฤษฎีหลักฐาน DS ถูกนำมาใช้อย่างแพร่หลายในการหลอมรวมข้อมูลแบบหลายเซ็นเซอร์ ในทฤษฎีหลักฐาน เพื่ออธิบายและจัดการกับความไม่แน่นอน ได้มีการนำเสนอแนวคิดของฟังก์ชันการแจกแจงความน่าจะเป็น ฟังก์ชันความเชื่อ และฟังก์ชันความน่าจะเป็น
1) ฟังก์ชันการแจกแจงความน่าจะเป็น
กำหนดให้ D เป็นพื้นที่ตัวอย่าง ข้อเสนอในฟิลด์จะแสดงโดยเซตย่อยของ D ฟังก์ชันการแจกแจงความน่าจะเป็นถูกกำหนดดังนี้
ตั้งค่าฟังก์ชัน M:

และเป็นไปตาม

เรียกว่าฟังก์ชันการแจกแจงความน่าจะเป็นบน

ฟังก์ชันความน่าจะเป็นพื้นฐานของ A
2) ฟังก์ชันความเชื่อและฟังก์ชันความน่าจะเป็น
ฟังก์ชันความเชื่อแสดงด้วยฟังก์ชัน Bel หรือที่เรียกว่าฟังก์ชันขีดจำกัดล่าง โดยที่ ฟังก์ชัน Bel (A) แสดงถึงระดับความเชื่อที่ว่าข้อเสนอ A เป็นจริง ฟังก์ชันความน่าจะเป็นแสดงด้วยฟังก์ชัน Pls(A) แสดงถึงระดับความเชื่อที่ไม่ปฏิเสธข้อเสนอ A [Bel(A), Pls(A)] เรียกว่าช่วงความน่าเชื่อถือของข้อเสนอ A
3) ฟังก์ชันการแจกแจงผลรวมความน่าจะเป็นแบบตั้งฉาก
เมื่อได้ฟังก์ชันการแจกแจงความน่าจะเป็นที่แตกต่างกันสองฟังก์ชันหรือมากกว่าจากหลักฐานเดียวกัน จำเป็นต้องรวมฟังก์ชันเหล่านั้นเข้าด้วยกัน กล่าวคือ ผลรวมเชิงมุมฉากของฟังก์ชันการแจกแจงความน่าจะเป็น ให้ n เป็นฟังก์ชันการแจกแจงความน่าจะเป็น ผลรวมเชิงมุมฉากของฟังก์ชันนี้ คือ สมการ (4):

ที่ไหน.
ถ้า K≠0 แล้วผลรวมมุมฉาก M เป็นฟังก์ชันการแจกแจงความน่าจะเป็น ถ้าไม่มีผลรวมมุมฉาก K=0 กล่าวคือ M1 และ M2 ข้อขัดแย้ง
ตามกรอบแนวคิดทั่วไปของการรวมข้อมูลและลักษณะเฉพาะของความผิดพลาดของหม้อแปลง DBN ถูกรวมเข้ากับการรวมข้อมูลและนำไปใช้ในการวินิจฉัยความผิดพลาดในบทความนี้ การวินิจฉัย DBN เป็นส่วนหนึ่งของกระบวนการของอินพุตระดับคุณลักษณะและเอาต์พุตระดับการตัดสินใจในแง่ของการรวมข้อมูล และทฤษฎีหลักฐาน DS หลอมรวมและให้เหตุผลกับหลักฐานต่างๆ ในกรอบเดียวกันและนำไปสู่การตัดสินใจที่เป็นหนึ่งเดียว ซึ่งเป็นส่วนหนึ่งของกระบวนการของอินพุตระดับการตัดสินใจและเอาต์พุตระดับการตัดสินใจ การผสมผสานนี้สามารถปรับปรุงความน่าเชื่อถือและความแม่นยำของการวินิจฉัยได้อย่างมาก ดังนั้น บทความนี้จึงได้สร้างแบบจำลองการวินิจฉัยการรวมข้อมูลแบบลำดับชั้นสำหรับความผิดพลาดหลายจุดของหม้อแปลงไฟฟ้าโดยอาศัยการผสมผสานทฤษฎีหลักฐาน DBN และ DS ดังแสดงใน รูปที่ 3พารามิเตอร์ของ DGA ได้แก่ H2, CH4, C2H6 และอื่นๆ ข้อมูลการทดสอบทางไฟฟ้า ได้แก่ ค่าสัมประสิทธิ์ความไม่สมดุลของขดลวด การสูญเสียไดอิเล็กทริกของขดลวด และกระแสไฟฟ้าที่ต่อลงดินของแกนกลาง
4. ตัวอย่าง PHM
บทความนี้ใช้แบบจำลองเครือข่ายความเชื่อเชิงลึก (DBNC) (ดังแสดงใน รูปที่ 4 คือแบบจำลอง DGA gas DBNC) อินพุตของแบบจำลองคือค่าปริมาณก๊าซลักษณะเฉพาะเจ็ดค่า (หลังจากการปรับมาตรฐาน) ของโครมาโทแกรมน้ำมันแบบออนไลน์ สุดท้าย เอาต์พุตของตัวจำแนก Softmax ด้านบนคือความน่าจะเป็นที่ตัวอย่างที่สอดคล้องกันจะอยู่ในสถานะที่แตกต่างกันตามลำดับ สถานะความน่าจะเป็นสูงสุดคือผลลัพธ์ของการจำแนก สุดท้าย ใช้ทฤษฎีหลักฐาน DS
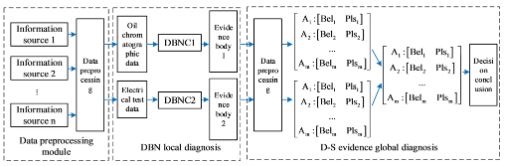
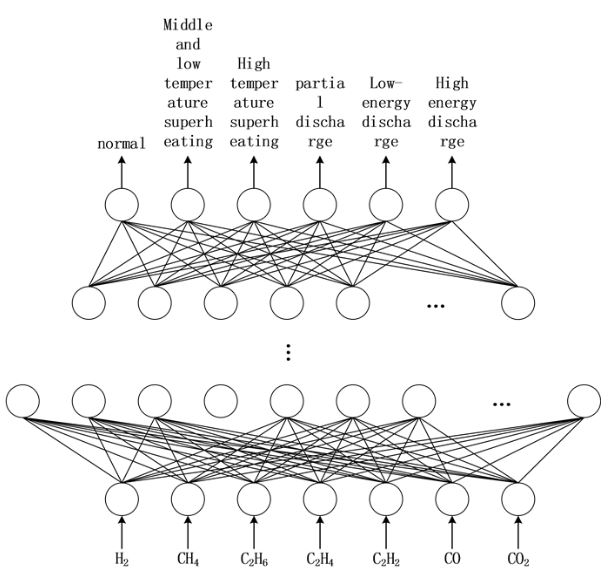
เพื่อรวมผลการวินิจฉัยเพื่อให้ได้ผลลัพธ์ขั้นสุดท้าย
บทความนี้ได้รวบรวมข้อมูลตัวอย่างหม้อแปลงไฟฟ้า 1,500 ตัวอย่าง ข้อมูลโครมาโทแกรมน้ำมันแสดงใน
ตารางที่ 1ในโครงการทดสอบไฟฟ้า พบว่าความต้านทานฉนวนของแกนกลาง ค่าสัมประสิทธิ์ความไม่สมดุลของความต้านทานกระแสตรงของขดลวด กระแสไฟฟ้าที่ต่อลงดินของแกนกลางเกินค่าที่แจ้งไว้ และค่าการทดสอบไฟฟ้าอื่นๆ อยู่ในเกณฑ์ปกติ ตัวต้านทานแบบพันลวดมีค่าเพียง 65 MΩ (ค่าที่แจ้งไว้คือ 1,000 MΩ) ค่าสัมประสิทธิ์ความไม่สมดุลของความต้านทานกระแสตรงของขดลวดเท่ากับ 2.95% (ค่าที่แจ้งไว้คือ 2%) กระแสไฟฟ้าที่ต่อลงดินของแกนกลางเท่ากับ 0.13 A (ค่าที่แจ้งไว้คือ 0.1 A)

การใช้เครื่องจำแนกประเภท DBNC เพื่อจำแนกประเภทข้อมูลตัวอย่าง พบว่าความแม่นยำของผลการวินิจฉัยจากข้อมูลโครมาโทแกรมน้ำมันสูงถึง 81.53% และความแม่นยำของผลการวินิจฉัยจากข้อมูลการทดสอบทางไฟฟ้าสูงถึง 78.83% เมื่อรวมผลการวินิจฉัยด้วยทฤษฎีหลักฐาน DS พบว่าความแม่นยำในการวินิจฉัยสูงถึง 88.56% จะเห็นได้ว่าผลการวินิจฉัยจากแบบจำลองการรวมข้อมูลหลายแหล่งสำหรับการวินิจฉัยข้อบกพร่องมีความแม่นยำสูงกว่าผลการวินิจฉัยจากแหล่งข้อมูลเดียวหรือน้อยกว่า
5. บทสรุป
บทความนี้พยายามนำเสนอแนวคิด PHM เข้าสู่สาขาหม้อแปลงไฟฟ้ากำลัง เพื่อให้เป็นระบบอ้างอิงที่สมบูรณ์สำหรับการบำรุงรักษาหม้อแปลงไฟฟ้ากำลังตามสภาพ ด้วยเหตุนี้ บทความนี้จึงเสนอแบบจำลองการวินิจฉัยแบบไฮบริดสำหรับขั้นตอนการวินิจฉัยข้อบกพร่องของวงจร PHM ของหม้อแปลงไฟฟ้ากำลัง ซึ่งใช้หลักการจำแนกประเภทเครือข่ายความเชื่อเชิงลึก (Deep Belief Network Classifier) และทฤษฎีหลักฐาน DS ผลการทดลองแสดงให้เห็นว่าผลการวินิจฉัยของแบบจำลองการวินิจฉัยมีประสิทธิภาพเหนือกว่าข้อมูลแหล่งเดียว ประสิทธิภาพของการรวมข้อมูลหลายแหล่งในการปรับปรุงความแม่นยำของการวินิจฉัยข้อบกพร่องของหม้อแปลงไฟฟ้ากำลังได้รับการพิสูจน์แล้ว




ผลิตภัณฑ์
December 20, 2025
การวินิจฉัยและการพยากรณ์ความผิดพลาดของหม้อแปลงไฟฟ้าขนาดใหญ่โดยอาศัยทฤษฎีหลักฐาน DBNC และ D-S
บทความนี้จะอธิบายวิธีการวินิจฉัยและคาดการณ์ความผิดพลาดในหม้อแปลงไฟฟ้าขนาดใหญ่
by
นักเขียนบทความ

