
ผลิตภัณฑ์
19
Jan
AI GPU ทํางานอย่างไร – ภายในตัวเร่งความเร็ว AI สมัยใหม่
ค้นพบวิธีที่ AI GPU ใช้การขนานขนาดใหญ่เพื่อบดขยี้โครงข่ายประสาทเทียมที่ซับซ้อน

ปัญญาประดิษฐ์ ( AI ) ได้พัฒนาอย่างรวดเร็วจากระบบที่ใช้กฎเกณฑ์แบบง่ายๆ ไปสู่โมเดลการเรียนรู้เชิงลึกที่ซับซ้อนสูง ซึ่งสามารถทำงานต่างๆ เช่น การจดจำภาพ การประมวลผลภาษาธรรมชาติ และการตัดสินใจแบบอัตโนมัติ เบื้องหลังการปฏิวัติครั้งนี้คือหนึ่งในนวัตกรรมฮาร์ดแวร์ที่ทรงพลังที่สุดในยุคปัจจุบัน นั่นคือ GPU สำหรับ AI (หน่วยประมวลผลกราฟิก) เดิมที GPU ถูกออกแบบมาเพื่อแสดงผลกราฟิกในเกม แต่ได้เปลี่ยนไปเป็น โปรเซสเซอร์ แบบขนานประสิทธิภาพสูงที่เร่งความเร็วในการทำงานของ AI GPU สำหรับ AI รุ่นใหม่จากบริษัทต่างๆ เช่น NVIDIA, AMD และ Intel ได้รับการออกแบบมาโดยเฉพาะเพื่อรองรับการคำนวณข้อมูลจำนวนมหาศาลที่จำเป็นสำหรับการฝึกฝนและการอนุมานของโครงข่ายประสาทเทียม บทความนี้จะเจาะลึกถึงวิธีการทำงานของ GPU สำหรับ AI โดยสำรวจสถาปัตยกรรมภายใน โมเดลการทำงาน ระบบหน่วยความจำ และบทบาทของมันในการเร่งความเร็วในการทำงานของ AI
AI GPU คืออะไร?
GPU สำหรับ AI คือหน่วยประมวลผลเฉพาะทางที่ได้รับการปรับแต่งมาเพื่อการคำนวณแบบขนาน โดยเฉพาะอย่างยิ่งเหมาะสำหรับการดำเนินการกับเมทริกซ์ที่ใช้ในการเรียนรู้เชิงลึก
แตกต่างจาก CPU ที่เน้นการประมวลผลแบบเรียงลำดับ GPU สามารถประมวลผลการทำงานหลายพันรายการพร้อมกัน ทำให้เหมาะสำหรับ:
- การฝึกเครือข่ายประสาทเทียม
- การประมวลผลภาพ
- การวิเคราะห์ข้อมูลขนาดใหญ่
- การจำลองทางวิทยาศาสตร์
CPU กับ GPU: เหตุใด GPU จึงครองตลาด AI
สถาปัตยกรรมซีพียู
- จำนวนคอร์น้อย (4–64 คอร์)
- ปรับให้เหมาะสมสำหรับงานตามลำดับ
- แคชขนาดใหญ่และตรรกะควบคุมที่ซับซ้อน
สถาปัตยกรรม GPU
- แกนขนาดเล็กนับพัน
- ปรับให้เหมาะสมสำหรับงานแบบขนาน
- แบนด์วิดท์หน่วยความจำสูง
ความแตกต่างที่สำคัญ
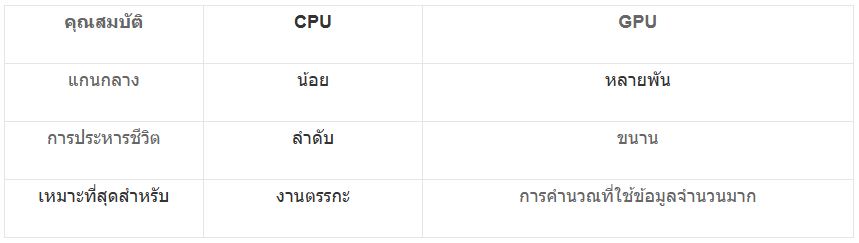
งานประมวลผล AI เกี่ยวข้องกับการคูณเมทริกซ์ ซึ่งสามารถประมวลผลแบบขนานได้ ทำให้ GPU ทำงานได้เร็วขึ้นอย่างมาก
แนวคิดหลัก: การประมวลผลแบบขนานในปัญญาประดิษฐ์
หัวใจสำคัญของการเร่งความเร็วด้วย GPU คือการประมวลผลแบบขนาน
โมเดล AI ทำงานกับเทนเซอร์ (อาร์เรย์หลายมิติ) ตัวอย่างเช่น:
- การคูณเมทริกซ์ในโครงข่ายประสาทเทียม
- การดำเนินการคอนโวลูชันในโครงข่ายประสาทเทียมแบบคอนโวลูชัน
การดำเนินการเหล่านี้สามารถแบ่งออกเป็นงานย่อยหลายพันงาน โดยแต่ละงานย่อยจะได้รับการประมวลผลพร้อมกันโดยแกนประมวลผลของ GPU
ภายในสถาปัตยกรรม GPU
หน่วยประมวลผลกราฟิก (GPU) สำหรับ AI สมัยใหม่ประกอบด้วย ส่วนประกอบ สำคัญหลายอย่าง
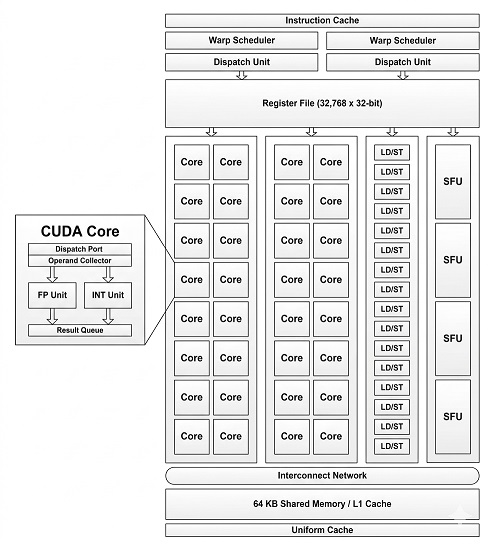
หน่วยประมวลผลแบบสตรีมมิ่ง (SMs)
GPU ถูกแบ่งออกเป็นหน่วยประมวลผลแบบสตรีมมิ่งหลายหน่วย (SMs)
SM แต่ละชุดประกอบด้วย:
- คอร์ CUDA (หน่วยประมวลผล)
- เทนเซอร์คอร์
- ตัวกำหนดตารางเวลาวาร์ป
- ทะเบียน
- หน่วยความจำที่ใช้ร่วมกัน
SM คือหน่วยประมวลผลหลักของ GPU
คอร์ CUDA
หน่วยประมวลผล CUDA เป็นหน่วยประมวลผลทางคณิตศาสตร์อย่างง่ายที่ทำหน้าที่ดังต่อไปนี้:
- ส่วนที่เพิ่มเข้าไป
- การคูณ
- การดำเนินการเชิงตรรกะ
หน่วยประมวลผล CUDA จำนวนหลายพันหน่วยช่วยให้ GPU สามารถประมวลผลหลายเธรดพร้อมกันได้
สีเทนเซอร์ (เอ็นจิ้น AI)
เทนเซอร์คอร์เป็นหน่วยประมวลผลเฉพาะที่ออกแบบมาสำหรับการคูณเมทริกซ์ ซึ่งเป็นหัวใจหลักของปัญญาประดิษฐ์ (AI)
พวกเขาดำเนินการต่างๆ เช่น:
- การคูณเมทริกซ์ FP16 / BF16
- การเร่งความเร็วการอนุมาน INT8
ตัวอย่างการดำเนินการ
D = A × B + C
หน่วยประมวลผล Tensor core สามารถคำนวณสิ่งนี้ได้ภายในรอบการทำงานของนาฬิกาเพียงหนึ่งรอบ ทำให้มีประสิทธิภาพสูงมากสำหรับงานด้าน AI
โมเดลการดำเนินการวาร์ป
เธรดใน GPU จะถูกจัดกลุ่มเป็นวาร์ป (โดยทั่วไปคือ 32 เธรด)
- เธรดทั้งหมดในกลุ่มเธรดจะประมวลผลคำสั่งเดียวกันพร้อมกัน
- นี่เรียกว่า SIMT (Single Instruction, Multiple Threads) หรือคำสั่งเดียวทำงานหลายเธรด
ตัวกำหนดตารางเวลาวาร์ป
ตัวกำหนดตารางเวลาวาร์ป:
- เลือกวาร์ปที่จะดำเนินการ
- สลับไปมาระหว่างวาร์ปเพื่อซ่อนความล่าช้าของหน่วยความจำ
วิธีนี้ช่วยให้ GPU สามารถรักษาอัตราการใช้งานที่สูงได้อย่างต่อเนื่อง
ลำดับชั้นของหน่วยความจำ GPU
หน่วยความจำมีความสำคัญอย่างยิ่งต่อประสิทธิภาพของ AI
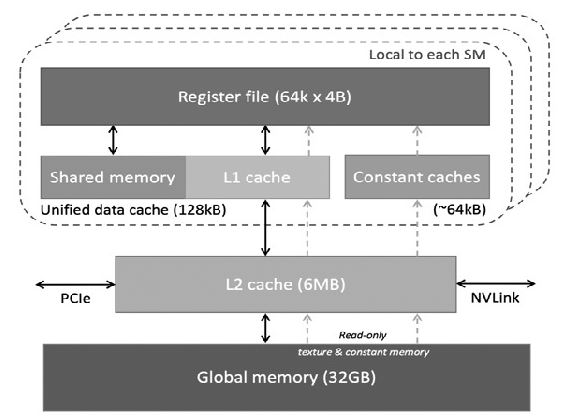
ทะเบียน
- หน่วยความจำที่เร็วที่สุด
- เฉพาะสำหรับแต่ละกระทู้เท่านั้น
หน่วยความจำที่ใช้ร่วมกัน
- แชร์ภายในโซเชียลมีเดีย
- ความหน่วงต่ำ
- ใช้สำหรับการนำข้อมูลกลับมาใช้ใหม่
แคช L1
- แคชภายในต่อ SM
- เร็วกว่าหน่วยความจำส่วนกลาง
แคช L2
- แชร์ผ่านโซเชียลมีเดียทุกช่องทาง
หน่วยความจำส่วนกลาง (HBM/GDDR)
GPU สำหรับ AI สมัยใหม่ใช้:
- HBM (หน่วยความจำแบนด์วิดท์สูง)
- แบนด์วิดท์: > 1 เทราไบต์/
จำเป็นอย่างยิ่งสำหรับโมเดล AI ขนาดใหญ่
วิธีการทำงานของ AI บน GPU?
ขั้นตอนที่ 1: การถ่ายโอนข้อมูล
ซีพียูส่งข้อมูลไปยังหน่วยความจำจีพียู
ขั้นตอนที่ 2: การเริ่มต้นเคอร์เนล
GPU ประมวลผลเคอร์เนล (ฟังก์ชันแบบขนาน)
ขั้นตอนที่ 3: การประมวลผลเธรด
เธรดหลายพันตัวทำงานพร้อมกัน
ขั้นตอนที่ 4: การคำนวณเมทริกซ์
หน่วยประมวลผล Tensor core ทำหน้าที่คูณเมทริกซ์
ขั้นตอนที่ 5: การจัดเก็บผลลัพธ์
ผลลัพธ์ถูกจัดเก็บไว้ในหน่วยความจำ GPU
การคูณเมทริกซ์: หัวใจสำคัญของปัญญาประดิษฐ์
โมเดล AI พึ่งพาปัจจัยหลายอย่างเป็นอย่างมาก ได้แก่:
- การคูณเมทริกซ์
- การดำเนินการคอนโวลูชัน
ตัวอย่าง:
ผลลัพธ์ = น้ำหนัก × ข้อมูลนำเข้า
GPU ช่วยเร่งความเร็วในการประมวลผลนี้โดยใช้:
- เกลียวคู่ขนาน
- เทนเซอร์คอร์
- การเพิ่มประสิทธิภาพหน่วยความจำ
การคำนวณความแม่นยำแบบผสม
GPU สำหรับ AI ใช้ความแม่นยำแบบผสมเพื่อปรับปรุงประสิทธิภาพ:
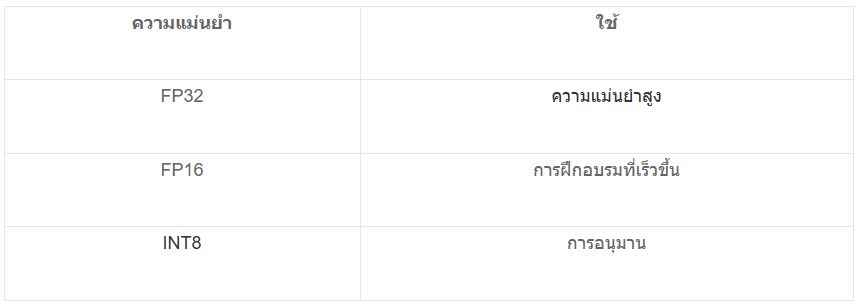
ความแม่นยำต่ำลง = การคำนวณเร็วขึ้น + ใช้หน่วยความจำน้อยลง
การฝึกฝน AI กับการอนุมาน
การฝึกอบรม
- ต้องการความแม่นยำสูง
- ใช้ FP32 / FP16
- การคำนวณหนัก
การอนุมาน
- ใช้โมเดลที่ผ่านการฝึกฝนแล้ว
- ใช้ INT8
- รวดเร็วและมีประสิทธิภาพยิ่งขึ้น
การไหลของข้อมูลภายใน GPU ของ AI
- ข้อมูลป้อนเข้าถูกโหลดเข้าสู่หน่วยความจำ
- เธรดจะดึงข้อมูลเข้าสู่รีจิสเตอร์
- หน่วยประมวลผลเทนเซอร์ทำหน้าที่คำนวณ
- ผลการเขียนกลับมา
ปัญหาคอขวดด้านหน่วยความจำ
แม้จะมีแกนประมวลผลที่ทรงพลัง การ์ดจอ (GPU) ก็ยังต้องเผชิญกับปัญหาดังต่อไปนี้:
- ความหน่วงของหน่วยความจำ
- ข้อจำกัดด้านแบนด์วิดท์
วิธีแก้ปัญหา:
- การแคช
- การรวมตัวของความทรงจำ
- การดึงข้อมูลล่วงหน้า
นวัตกรรม GPU AI สมัยใหม่
หน่วยความจำแบนด์วิดท์สูง (HBM)
- การถ่ายโอนข้อมูลที่รวดเร็วยิ่งขึ้น
ระบบมัลติจีพียู
- การประมวลผลแบบขนานบน GPU
เทคโนโลยี NVLink
- การสื่อสาร GPU ความเร็วสูง
คำแนะนำเฉพาะสำหรับ AI
- ออกแบบมาเพื่อการเรียนรู้เชิงลึกโดยเฉพาะ
ตัวอย่างจริง: GPU AI ของ NVIDIA
การ์ดจอ GPU รุ่นใหม่ๆ จาก NVIDIA ประกอบด้วย:
- เทนเซอร์คอร์
- คอร์ RT
- การกำหนดตารางเวลาขั้นสูง
ตัวอย่าง GPU:
- เอ100
- เอช100
- แบล็กเวลล์
การประยุกต์ใช้ GPU ใน AI
- รถยนต์ไร้คนขับ
- การถ่ายภาพทางการแพทย์
- การประมวลผลภาษาธรรมชาติ
- หุ่นยนต์
- ปัญญาประดิษฐ์สำหรับการเล่นเกม
ข้อดีของ GPU สำหรับ AI
- ความขนานจำนวนมหาศาล
- อัตราการประมวลผลสูง
- การคำนวณเมทริกซ์ที่มีประสิทธิภาพ
- สถาปัตยกรรมที่ปรับขนาดได้
ข้อเสีย
- การใช้พลังงานสูง
- ฮาร์ดแวร์ราคาแพง
- การเขียนโปรแกรมที่ซับซ้อน
อนาคตของ GPU สำหรับ AI
แนวโน้มในอนาคต ได้แก่:
- การคำนวณด้วยโฟตอนิกส์
- ชิปนิวโรโมฟิก
- การเร่งความเร็วควอนตัม
คำถามที่พบบ่อย
AI GPU คืออะไร?
GPU สำหรับ AI คือหน่วยประมวลผลที่ได้รับการปรับแต่งมาเพื่อการคำนวณแบบขนาน โดยเฉพาะอย่างยิ่งสำหรับการดำเนินการกับเมทริกซ์ที่ใช้ในปัญญาประดิษฐ์
เหตุใดจึงมีการใช้ GPU ใน AI?
พวกมันสามารถประมวลผลการทำงานหลายพันรายการพร้อมกันได้ ทำให้เหมาะอย่างยิ่งสำหรับเครือข่ายประสาทเทียม
Tensor Core คืออะไร?
เทนเซอร์คอร์เป็นหน่วยประมวลผลเฉพาะที่ออกแบบมาสำหรับการคูณเมทริกซ์อย่างรวดเร็วในงานด้านปัญญาประดิษฐ์ (AI)
โครงสร้างลำดับชั้นของหน่วยความจำ GPU คืออะไร?
ประกอบด้วยรีจิสเตอร์ หน่วยความจำร่วม แคช และหน่วยความจำส่วนกลาง ซึ่งจัดเรียงตามความเร็วและขนาด
การฝึกฝนและการอนุมานแตกต่างกันอย่างไร?
การฝึกฝนเป็นการสร้างแบบจำลอง ในขณะที่การอนุมานจะนำแบบจำลองนั้นไปใช้ในการทำนาย
GPU สำหรับ AI ได้กลายเป็นหัวใจสำคัญของปัญญาประดิษฐ์สมัยใหม่ ด้วยการทำให้สามารถประมวลผลแบบขนานขนาดใหญ่ เข้าถึงหน่วยความจำความเร็วสูง และมีฮาร์ดแวร์เฉพาะทางสำหรับการดำเนินการเมทริกซ์ สถาปัตยกรรมของ GPU ซึ่งสร้างขึ้นจากมัลติโปรเซสเซอร์แบบสตรีมมิ่ง คอร์เทนเซอร์ และหน่วยความจำแบนด์วิดท์สูง ช่วยให้สามารถจัดการกับการคำนวณที่ซับซ้อนซึ่งจำเป็นสำหรับการฝึกฝนและการใช้งานโมเดล AI ได้อย่างมีประสิทธิภาพ ในขณะที่ AI ยังคงพัฒนาต่อไป GPU จะยังคงเป็นหัวใจสำคัญของนวัตกรรม ขับเคลื่อนความก้าวหน้าในสาขาต่างๆ ตั้งแต่การดูแลสุขภาพไปจนถึงระบบอัตโนมัติ การทำความเข้าใจวิธีการทำงานของ GPU สำหรับ AI จะให้ข้อมูลเชิงลึกที่มีค่าเกี่ยวกับอนาคตของการคำนวณและเทคโนโลยีที่กำลังกำหนดรูปแบบโลกสมัยใหม่




ผลิตภัณฑ์
April 9, 2026
AI GPU ทํางานอย่างไร – ภายในตัวเร่งความเร็ว AI สมัยใหม่
ค้นพบวิธีที่ AI GPU ใช้การขนานขนาดใหญ่เพื่อบดขยี้โครงข่ายประสาทเทียมที่ซับซ้อน
by
นักเขียนบทความ

