
ผลิตภัณฑ์
19
Jan
สถาปัตยกรรมฮอปเปอร์อธิบาย: ตั้งแต่ SMs จนถึงคำสั่ง DPX
เรียนรู้ว่าการก้าวกระโดดทางสถาปัตยกรรมของ Hopper เปลี่ยนการประมวลผลอัลกอริทึมที่ซับซ้อนได้อย่างไร

สถาปัตยกรรม Hopper ที่เปิดตัวโดย NVIDIA ในเดือนมีนาคม 2022 เป็นความก้าวหน้าในเทคโนโลยี GPU ในฐานะผู้สืบทอดสถาปัตยกรรม Ampere Hopper แสดงถึงก้าวสําคัญต่อไปของ NVIDIA ในการขับเคลื่อนโมเดล AI ขั้นสูง การจําลองทางวิทยาศาสตร์ และการประมวลผลของศูนย์ข้อมูลสถาปัตยกรรม AI GPU นี้ตั้งชื่อตาม Grace Hopper ผู้บุกเบิกด้านวิทยาการคอมพิวเตอร์ โดยนําเสนอนวัตกรรมที่สําคัญ เช่น Streaming Multiprocessors (SMs) ที่ออกแบบใหม่, Tensor Cores เจนเนอเรชั่นที่สี่, Transformer Engine อันทรงพลัง, ระบบย่อยหน่วยความจําขั้นสูง และคําสั่ง DPX ใหม่คุณสมบัติเหล่านี้ทําให้ GPU ที่ใช้ Hopper เช่น NVIDIA H100 GPU เหมาะอย่างยิ่งสําหรับการฝึกอบรม AI ขนาดใหญ่ การประมวลผลประสิทธิภาพสูง (HPC) และเวิร์กโหลดการอนุมาน AI ที่ซับซ้อน
ในบทความนี้ เราจะเจาะลึกลงไปในสถาปัตยกรรมไมโครของ Hopper โดยตรวจสอบส่วนประกอบหลัก เทคโนโลยีที่ขับเคลื่อนประสิทธิภาพ และวิธีปรับให้เหมาะสมสําหรับปริมาณงาน AI และ HPC นอกจากนี้ เราจะสํารวจประโยชน์ ความท้าทาย และการใช้งานในโลกแห่งความเป็นจริง
สถาปัตยกรรม Hopper คืออะไร?
Hopper เป็นสถาปัตยกรรมไมโคร GPU ของ NVIDIA ที่ออกแบบมาโดยเฉพาะสําหรับปริมาณงาน AI และ HPC ขับเคลื่อน NVIDIA H100 GPU และแนะนําสิ่งแรกมากมายในการออกแบบ GPU รวมถึงความแม่นยํา FP8, Transformer Engine และคําสั่ง DPXHopper สร้างขึ้นโดยใช้กระบวนการ TSMC 4N ซึ่งเป็นโหนดการผลิต 4nm แบบกําหนดเองที่บรรจุทรานซิสเตอร์ 80 พันล้านตัวไว้ในแม่พิมพ์เดียวคําหลักเหล่านี้ช่วยให้บทความจัดอันดับสําหรับคําถามทางเทคนิคที่หลากหลายที่เกี่ยวข้องกับสถาปัตยกรรม NVIDIA GPU และ GPU ประสิทธิภาพสูง
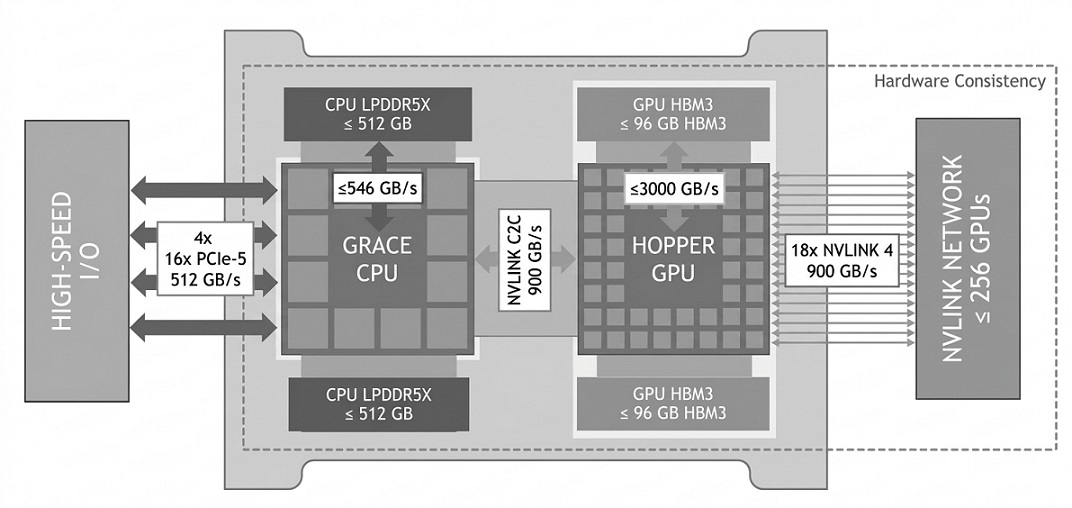
สตรีมมิ่งมัลติโปรเซสเซอร์ (SM) ในสถาปัตยกรรม Hopper
สตรีมมิ่งมัลติโปรเซสเซอร์ (SM) เป็นหัวใจสําคัญของสถาปัตยกรรม GPU ใน Hopper SM ได้รับการออกแบบใหม่เพื่อรองรับเธรดที่มากขึ้นอย่างมีนัยสําคัญและให้ปริมาณงานที่ดีขึ้น NVIDIA H100 มี SM สูงสุด 144 ตัว โดยแต่ละตัวสามารถรองรับเธรดพร้อมกันได้ 2,048 เธรด SM เหล่านี้คล้ายกับคอร์ CPU ในฟังก์ชัน แต่ได้รับการปรับให้เหมาะสมสําหรับการประมวลผลแบบขนาน SM แต่ละตัวประกอบด้วย:
- ALU จํานวนเต็มและทศนิยม
- โหลด/จัดเก็บหน่วย
- ลงทะเบียนไฟล์
- หน่วยความจําที่ใช้ร่วมกัน/แคช L1
- แกนเทนเซอร์
สถาปัตยกรรม SM ใน Hopper GPU ช่วยให้สามารถทํางานพร้อมกันและขนานได้สูงขึ้น ซึ่งจําเป็นสําหรับการฝึกอบรม AI ขนาดใหญ่และการคํานวณทางวิทยาศาสตร์ตัวกําหนดตารางเวลาคําสั่งและลําดับชั้นหน่วยความจําใหม่ช่วยให้มั่นใจได้ว่า SM ยังคงใช้งานได้อย่างเต็มที่ในปริมาณงานที่หลากหลาย
Tensor Cores และการประมวลผลที่มีความแม่นยําแบบผสม
Hopper เปิดตัว Tensor Cores เจนเนอเรชั่นที่สี่ที่รองรับรูปแบบความแม่นยําหลายรูปแบบ ได้แก่ FP64, FP32, FP16 และ FP8 ใหม่ทั้งหมดความยืดหยุ่นนี้ช่วยให้โมเดล AI สามารถใช้รูปแบบข้อมูลที่เหมาะสมที่สุดสําหรับแต่ละเลเยอร์หรือการทํางาน โดยสร้างสมดุลระหว่างประสิทธิภาพและความแม่นยํา
ความแม่นยํา FP8:
หนึ่งในแง่มุมที่เปลี่ยนแปลงมากที่สุดของ Hopper คือการรองรับ FP8 ซึ่งเป็นรูปแบบใหม่ที่มีความแม่นยําต่ําซึ่งเหมาะสําหรับเวิร์กโหลด AIGPU ที่มีความแม่นยํา FP8 ช่วยให้คํานวณได้เร็วขึ้นและลดการใช้หน่วยความจําเมื่อเทียบกับ FP16 ทําให้เหมาะสําหรับการฝึกโมเดลภาษาขนาดใหญ่ (LLM) โดยไม่ลดทอนความแม่นยําของโมเดล
Tensor Cores ใน Hopper มอบ:
- การฝึกอบรม AI เร็วขึ้นสูงสุด 9 เท่าเมื่อเทียบกับ A100
- การอนุมาน AI เร็วขึ้นสูงสุด 30 เท่า
- ปริมาณงาน FP8 มากกว่า 1,000 TFLOPS
เครื่องยนต์หม้อแปลง
Transformer Engine เป็นหน่วยที่สร้างขึ้นตามวัตถุประสงค์ใน Hopper ที่ออกแบบมาเพื่อเร่งความเร็วโมเดลที่ใช้ Transformer รวมถึง GPT, BERT และ T5 จัดการความแม่นยําแบบไดนามิกโดยใช้ FP8 และ FP16 เพื่อเพิ่มประสิทธิภาพสูงสุดโดยไม่ลดทอนคุณภาพของโมเดลเอ็นจิ้นนี้มีผลกระทบอย่างยิ่งในรุ่น NLP ขนาดใหญ่ที่ความเร็วและประสิทธิภาพเป็นสิ่งสําคัญในการทดสอบเกณฑ์มาตรฐาน H100 ที่ใช้ Transformer Engine สามารถสร้างโทเค็นได้เร็วกว่า A100 GPU ถึงสองเท่า
NVLink 4.0 และ GPU Interconnect
รากฐานที่สําคัญอีกประการหนึ่งของประสิทธิภาพของ Hopper คือ NVLink 4.0 การเชื่อมต่อระหว่างกันรุ่นที่สี่นี้ช่วยให้สามารถสื่อสารระหว่าง GPU ได้อย่างรวดเร็วเป็นพิเศษในการกําหนดค่าหลาย GPU
ฟีเจอร์หลัก:
- แบนด์วิดท์สูงสุด 900 GB/s ต่อ GPU
- 18 NVLink เลนที่ความเร็ว 50 GB/s แต่ละเลน
- ปรับปรุงเวลาแฝงและลดปัญหาคอขวด
NVLink 4.0 เป็นสิ่งจําเป็นสําหรับการสร้างระบบเอ็กซาสเกลโดยใช้ GPU H100 หลายร้อยตัวทําให้มั่นใจได้ว่า GPU แต่ละตัวสามารถแบ่งปันข้อมูลได้อย่างราบรื่น ทําให้สามารถประมวลผลแบบขนานขนาดใหญ่สําหรับการฝึกอบรมโมเดล AI และปริมาณงานการจําลอง
โปรดดูลิงค์นี้เพื่อทราบข้อมูลเพิ่มเติมเกี่ยวกับชิป NVIDIA GB200 AI
MIG (GPU หลายอินสแตนซ์)
Hopper GPU มีเทคโนโลยี MIG (Multi-Instance GPU) เจนเนอเรชั่นที่สอง ซึ่งช่วยให้สามารถแบ่งพาร์ติชัน GPU H100 ตัวเดียวออกเป็นอินสแตนซ์แยกกันได้สูงสุด 7 อินสแตนซ์แต่ละอินสแตนซ์ทํางานด้วยทรัพยากรการประมวลผล แคช และหน่วยความจําแบบแยกส่วน
สิทธิประโยชน์:
- ปรับปรุงการใช้ทรัพยากร
- การรักษาความปลอดภัยและการแยกที่เพิ่มขึ้นสําหรับปริมาณงานบนคลาวด์
- โปรไฟล์ประสิทธิภาพที่ปรับให้เหมาะกับผู้ใช้ที่แตกต่างกัน
MIG เหมาะอย่างยิ่งสําหรับศูนย์ข้อมูลและองค์กรที่ให้บริการ AI-as-a-Service เนื่องจากช่วยให้สามารถแชร์ GPU ได้อย่างปลอดภัยและมีประสิทธิภาพ
คําแนะนํา DPX
Hopper แนะนํา DPX (Dynamic Programming Extensions) เพื่อเร่งอัลกอริทึมเฉพาะที่ใช้ในสาขาต่างๆ เช่น:
- จีโนมิกส์
- การวิเคราะห์กราฟ
- การเพิ่มประสิทธิภาพห่วงโซ่อุปทาน
- การสร้างแบบจําลองโรค
คําสั่ง DPX ใหม่เหล่านี้ถูกนําไปใช้ในฮาร์ดแวร์และลดรันไทม์ของอัลกอริธึมการเขียนโปรแกรมแบบไดนามิกได้อย่างมาก ซึ่งโดยทั่วไปจะใช้หน่วยความจําและการประมวลผลมากตัวอย่างเช่น DPX สามารถเร่งอัลกอริทึม Smith-Waterman และ Needleman-Wunsch ที่ใช้ในชีวสารสนเทศศาสตร์
ระบบหน่วยความจําและ HBM3
Hopper GPU มีระบบย่อยหน่วยความจําล้ําสมัยที่สร้างขึ้นจาก HBM3 (High Bandwidth Memory 3)NVIDIA H100 GPU เวอร์ชัน SXM ประกอบด้วย:
- HBM80 ขนาด 3 GB
- แบนด์วิดท์ 3.35 TB/s
คุณสมบัติหน่วยความจําอื่นๆ:
- แคช L2 ที่ใหญ่ขึ้น (50 MB)
- แคช L1 ต่อ SM และหน่วยความจําที่ใช้ร่วมกัน
- แบนด์วิดท์ที่สูงขึ้นสําหรับงานที่ต้องใช้หน่วยความจํามาก
ระบบหน่วยความจําความเร็วสูงนี้รองรับการเคลื่อนย้ายข้อมูลที่รวดเร็ว ซึ่งจําเป็นสําหรับปริมาณงาน AI ที่มีชุดข้อมูลขนาดใหญ่
ลําดับชั้นของ CUDA และระบบนิเวศซอฟต์แวร์
Hopper GPU ยังคงรองรับโมเดลการเขียนโปรแกรม CUDA ซึ่งได้รับการพัฒนาเพื่อใช้ประโยชน์จากความก้าวหน้าทางสถาปัตยกรรมได้ดียิ่งขึ้นนักพัฒนา CUDA สามารถใช้ประโยชน์จาก:
- ดึกดําบรรพ์ระดับวาร์ป
- กลุ่มสหกรณ์
- ปรับปรุงการใช้หน่วยความจําที่ใช้ร่วมกัน
NVIDIA ยังมีระบบนิเวศของไลบรารีและเครื่องมือที่ปรับให้เหมาะสม ได้แก่:
- คิวบลาส.
- คิวดีเอ็นเอ็น.
- เทนซอร์อาร์ที
- ระบบ Nsight และการประมวลผล
เครื่องมือเหล่านี้ช่วยให้นักพัฒนาดีบัก โปรไฟล์ และเพิ่มประสิทธิภาพแอปพลิเคชันที่ขับเคลื่อนด้วย Hopper ได้อย่างมีประสิทธิภาพ
กรณีการใช้งานและแอปพลิเคชันในโลกแห่งความเป็นจริง
สถาปัตยกรรม Hopper เหมาะสําหรับ:
- การฝึกอบรมโมเดลภาษาขนาดใหญ่ (LLM)
- Generative AI (ข้อความ รูปภาพ วิดีโอ)
- การเรียนรู้แบบเสริมแรงเชิงลึก
- การจําลองสภาพอากาศและภูมิอากาศ
- การค้นพบยาและจีโนม
- การตรวจจับการฉ้อโกงแบบเรียลไทม์ในฟินเทค
- การฝึกอบรมยานยนต์ไร้คนขับ
- ความสามารถในการเร่งทั้งการอนุมานและการฝึกอบรมทําให้เป็นโซลูชันแบบครบวงจรสําหรับบริษัทที่ปรับใช้ระบบ AI ขนาดใหญ่
ข้อดีและข้อเสียของสถาปัตยกรรม Hopper
จุดเด่น:
- ประสิทธิภาพ AI และ HPC ที่ยอดเยี่ยม
- รองรับ FP8 precision GPU และ Transformer Engine
- การเชื่อมต่อระหว่างกันที่ทรงพลัง (NVLink 4.0)
- ความสามารถในการปรับขนาดที่ยอดเยี่ยมด้วย MIG (Multi-Instance GPU)
- คําแนะนําฮาร์ดแวร์เฉพาะ (DPX)
จุดด้อย:
- ใช้พลังงานสูง (สูงสุด 700W)
- แพง.
- ต้องใช้โครงสร้างพื้นฐานขั้นสูง (การระบายความร้อน, PSU, การเชื่อมต่อระหว่างกัน)
สถาปัตยกรรม Hopper เป็นตัวเปลี่ยนเกมในการประมวลผล GPU ด้วยนวัตกรรมต่างๆ เช่น ความแม่นยําของ FP8, Tensor Cores เจนเนอเรชั่นที่สี่, NVLink 4.0 และคําสั่ง DPX มันผลักดันขอบเขตของสิ่งที่เป็นไปได้ใน AI และ HPC ไม่เพียงแต่ให้ความเร็วแบบทวีคูณในการฝึกอบรมและการอนุมาน แต่ยังปรับปรุงประสิทธิภาพผ่าน MIG และการเขียนโปรแกรมแบบไดนามิกที่เร่งด้วยฮาร์ดแวร์ Hopper ของ NVIDIA เป็นมากกว่าสถาปัตยกรรม GPU แต่เป็นรากฐานสําหรับอนาคตของการประมวลผลแบบเร่งความเร็ว




ผลิตภัณฑ์
March 27, 2026
สถาปัตยกรรมฮอปเปอร์อธิบาย: ตั้งแต่ SMs จนถึงคำสั่ง DPX
เรียนรู้ว่าการก้าวกระโดดทางสถาปัตยกรรมของ Hopper เปลี่ยนการประมวลผลอัลกอริทึมที่ซับซ้อนได้อย่างไร
by
นักเขียนบทความ

